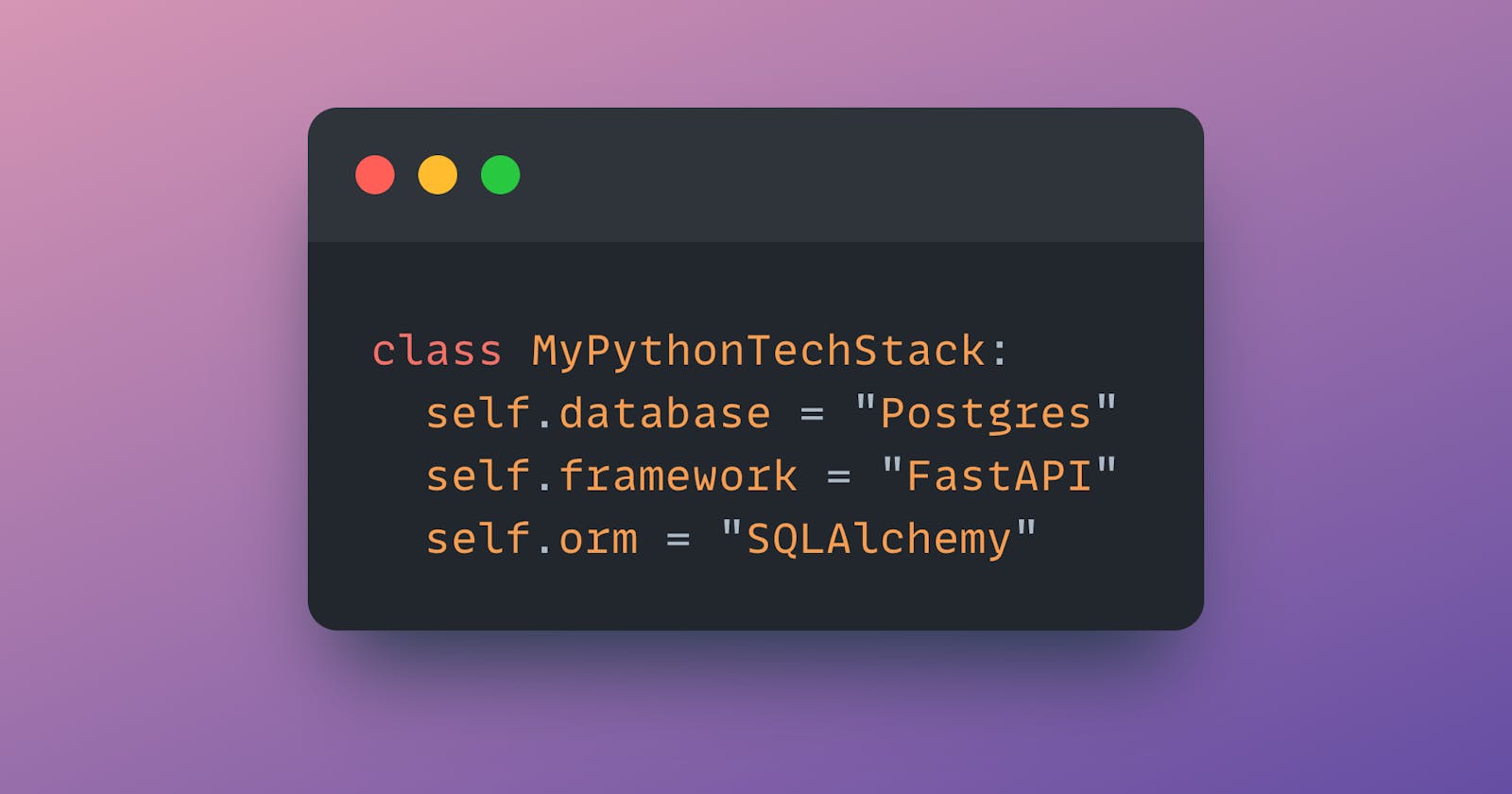
How to build a fast and scalable API in Python
Using FastAPI, Postgres, and SQLAlchemy!


Introduction
Today I'll be going through what I have found to be the best Python tech stack for building maintainable and scalable APIs. While most tech stack articles look at the full-stack, I like to decouple the two. As a backend service ideally should be generic in how it can be used (REST, GraphQL, etc.), any frontend framework should work well with a robust backend service.
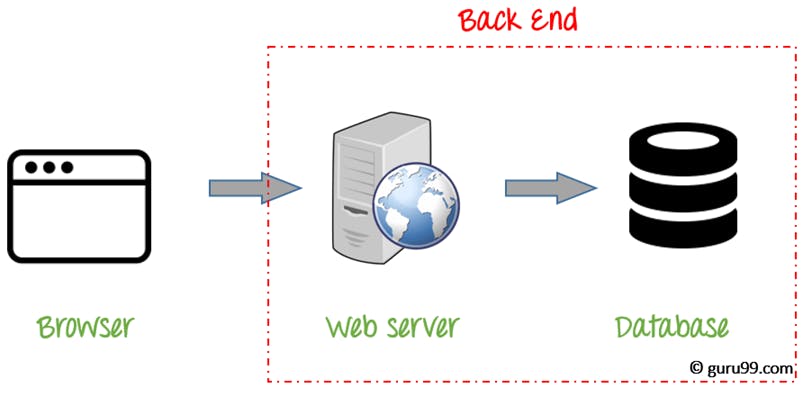
Shown by the simple, yet informative, diagram below we'll be covering how to setup the web server and database for any mobile or web application.
Web Framework
At the core of it all is the web framework used to construct the API layer of the backend. While I've worked with Django, Django Rest Framework (DRF), and Flask, I've found FastAPI to be the easiest to use while being the most performant so I've stuck with it.
FastAPI
Although first introduced in 2018, FastAPI is already a staple of the Python community. With 43K stars at the time of writing, it has created a huge wave in just a few years so lets look at some of it's unique features to see if it's really worth it.
Blazing fast (for Python)
Built on top of Starlette (the fastest ASGI framework for Python), it is able to introduce a complex set of API feature while remaining quite fast.
Schema Validation
Built on top of Pydantic, FastAPI is able to validate requests and responses all with Python's native "types".
Automatic Interactive Documentation
Using OpenAPI, FastAPI automatically generates an interactive documentation page from your endpoint docstrings. Additionally, you can use it to ping your endpoints and even authenticate using specific protocols.
Example
Now let's look how to setup a simple FastAPI instance (with no database for now).
Then launch it with uvicorn:
uvicorn fastapi-example:app
And vòila! You have your interactive docs at http://localhost:8000/docs
Database
Now while not required for a backend service, it's almost guaranteed that you'll need a database at some point. When it comes to that, I typically default to Postgres. Although there's been a lot of talk in the NoSQL space with things like MongoDB, Google's Firebase, and many more, I have my concerns as a default.
As I mostly use Firebase, I'll talk about my concerns for it specifically. While it's a great database for simple apps that are non-relational, it starts to really show it's flaws when more complex querying is needed. With no native structure for relations across tables (called collections by Firebase), a lack of aggregation queries, and mixed support for batch operations, it has some issues as the complexity of an application scales. If a simpler, non-relational, database works for your app then I'd recommend Firebase as it's cheaper and easier-to-use, but I'd caution about using it as a default without thinking about it's flaws.
Postgres
So I guess this section could really just be "a mature RDBMS" but that doesn't have the same pop as Postgres. When making an application that (you hope) will scale, I think it's best to go with Postgres and here's why:
- Mature enough to have a solid community, good documentation, and third-party packages.
- Efficient at handling a large amount of read and write operations concurrently
- Can handle complex data types like geometric, enum, json, etc.
- Open source under the PostgreSQL License
While there are others like MySQL which is more performant when the operations of focused on reads, most applications have a mix of reads and writes so I typically chose Postgres over MySQL.
Database client / ORM
While a database client may seem too in the weeds for a "techstack" article, I think there's a reason. As a lot of people in the Python community use Django, which has a built-in ORM, I thought it'd be good to show a powerful ORM for people looking to make the switch.
SQLAlchemy
Say hi to SQLAlchemy! It really is one of the most impressive open-source packages that I've worked with in a while. With the ORM being the most popular part of it, I'll give a brief introduction into how it can be used with any of their supported databases. For a full set of features, also check out their features page.
Example
Lets take a look at an SQLAlchemyORM example!
First, we use the Base variable to let SQLAlchemy know that this class User is a table to be used by the ORM. Next we create the table in a Postgres database. Then we create a database session using the engine. And lastly, we create and then retrieve a new user. I don't know about you but it always impresses me with how clean the code is. In only a few lines, we're able to setup an object, create a table for it, start a session, and interact with the database!
The last great thing about SQLAlchemy is it intelligently knows how to interact with a database just from the url given to create_engine. We could swap out the Postgres url with a MySQL url and the code would work the exact same!
Summary
Thanks for reading! A few resources I thought were overload for this article but are good for future reading are alembic for SQLAlchemy database migrations and the FastAPI deployment documentation.
If you're interested in more articles about maintainable and scalable backend services, checkout out my other articles,